
Scaling the Big Peer Store
The Ditto Big Peer may appear like any another peer in a mesh, but it is different. It is a distributed database that is made up of a number of components, including:
- Subscription Servers that communicate with Small Peer meshes using the Ditto Replication Protocol
- API Servers that host the HTTP API
- A distributed transaction log
- A partitioned and replicated distributed database: the Big Peer Store
- A Change Data Capture (CDC) system that monitors changes and provides them to third-party systems, either through pre-defined Kafka topics or WebHooks.
This makes the Big Peer both a system of record with data at rest, as well as a a conduit of data from existing data systems, into the mesh, and back out to existing systems.
This article focuses on the Big Peer Store, specifically how the Store scales up and down, while continuing to provide transactional causal consistency.
The Big Peer Store
To understand how we can scale the Big Peer Store while maintaining functionality, it is first necessary to describe how it works. What follows describes the key primitives of its design and shows how we scale the system using transitions.
The Big Peer Store is inspired by the paper PaRiS: Causally Consistent Transactions with Non-blocking Reads and Partial Replication.
Partitioned
The Big Peer is a distributed database that stores Documents as CRDTs. It can store more documents than can fit on a cheap commodity disk, and so it partitions its state by storing subsets of documents on multiple Store Nodes.
To ensure a balanced partitioning mechanism, the Store uses Random Slicing, partitioning the available keyspace using the range of integers from 0 to 2^64 − 1. Each partition of the Store is responsible for multiple sub-ranges of this keyspace, called Intervals. These sub-ranges don't need to be contiguous, as random slicing uses the Cut-Shift algorithm, which might take sections of pre-existing partitions and use them to make new partitions. This ensures that the minimal amount of data is moved when creating partitions.
Using this strategy, each document identifier is hashed to produce an u64, which in turn
is mapped to a specific Interval, stored by a particular Store node.

Replicated
The other axis of distribution for the Big Peer Store is
replication. Each partition is fully replicated, resulting in storing
multiple copies of each document. For simplicity's sake, we can say that every
Big Peer Store cluster is made of P partitions replicated on R Store
nodes. For example, a cluster of 3 partitions with 2 replicas will
have 6 store nodes.
The Log, Transactions, and Transaction Timestamps
All data enters the Big Peer Store via the Transaction Log. Each
transaction may contain updates, inserts, and deletes for many
documents. The log is totally ordered, where each transaction gets
assigned a position in the log (the first transaction gets position 1, the second 2, and so on).
In the Big Peer Store these log positions become Transaction Timestamps, such that the logical
time of a transaction is represented by a single scalar value.
Each Big Peer Store Node consumes from the log, sequentially and independently. Although a transaction may affect documents that are owned by different partitions, each Store Node will only store modifications for the documents that it owns. Independently of this, each Store Node records the fact that it has seen a given transaction by storing the Transaction Timestamp in its metadata.
Periodically the Store Nodes gossip to each other the maximum Transaction Timestamp that they have committed to disk.
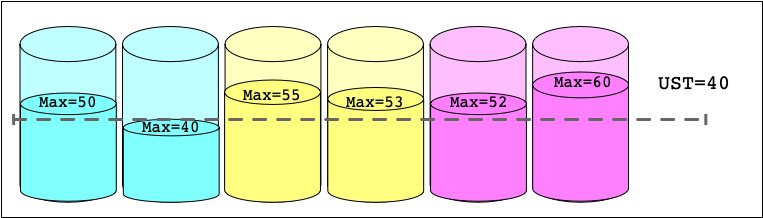
Universally Stable Timestamp (UST)
The Universally Stable Timestamp (UST) represents the timestamp of the latest transaction that is guaranteed to be stored (stable) at every node, meaning any read at that timestamp will be consistent. The UST is calculated by computed the minimum of the latest stored transaction, for every Store Node in the system.
NOTE: We actually use a subset of the Store Nodes to calculate a stable timestamp, but explaining how detracts from the purpose of the article.
Store Versions
Each Transaction Timestamp can be thought of as a version of the
database, meaning that a store node can contain multiple versions for a given document.
This means that if a read starts when the UST is 100, it must be allowed to complete consistently,
alongside another read at a UST of 200.
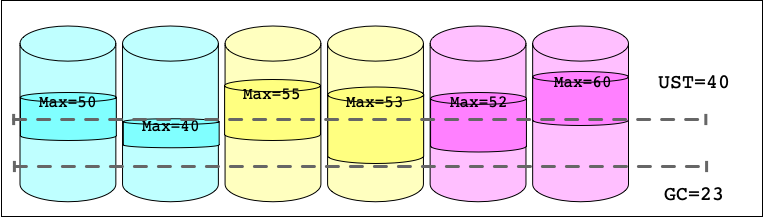
Garbage Collection Timestamp
Keeping all versions of all documents forever is prohibitively expensive. Instead, the Big Peer Store Nodes independently perform garbage collection of document versions that will never be read again.
The Garbage Collection Timestamp (GC Timestamp) is much like the UST. When a read transaction is served by a Store Node, it gets assigned a Read Timestamp equal to the UST at that node. Each Store Node gossips their lowest active Read Timestamp, and in turn computes the GC Timestamp by taking the minimum of all read transaction timestamps. Any version below the GC Timestamp can be discarded as that version will never be read again. For a given Store Node with no in-flight reads, its local GC Timestamp will be equal to its view of the UST.
One can imagine a sliding window of visible versions, with the lower edge being the GC Timestamp, and the upper edge the UST.
Cluster Configurations
As described above, the Big Peer Store is made up of Store Nodes, each being a replica of a partition. The partitions themselves are made up of intevals of the keyspace. All this information is stored in the Cluster Configuration, which aids in mapping Intervals to partitions, and partitions to store nodes.
Epochs and Configuration-aware Read Timestamps
Each Cluster Configuration has a unique monotonically increasing identifier,
starting from 0 (the empty cluster configuration). This identifier is also
called the Cluster Configuration Epoch, or Epoch for short.
Recall that we described Read Timestamps earlier as a single scalar. We now augment this concept by making read transactions Configuration-aware, such that a Read Timestamp is pair of Epoch and Transaction Timestamp (UST). Only nodes in the current Cluster Configuration co-ordinate read transactions.
This pair of scalars, rising monotonically, are used to manage cluster Transitions.
Transitions
Transitions are the process by which the Big Peer Store moves from the Current Cluster Configuration to the Next Cluster Configuration, allowing the Big Peer Store to scale up and down. The number of partitions and replicas in a Cluster Configuration describe the size and shape of the Big Peer Store.
For example, assume that the Big Peer Store is deployed with a single partition and two replicas (thus two Big Peer Store Nodes running).
To scale up the deployment, we add a new partition. This means that half
the documents that were owned by partition 1 (P1) will now be
owned by partition 2 (P2). The Transition must be performed in such
a way that writes and reads progress, and all queries remain causally
consistent.
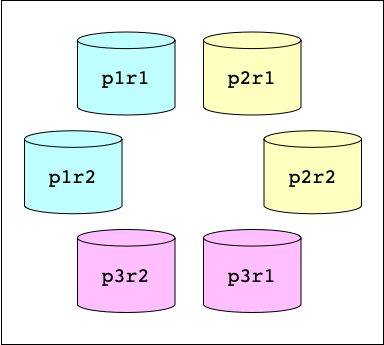
Using this concrete example (1P*2R -> 2P*2R) we can name the Big
Peer Store Nodes P1R1 and P1R2 for the two original nodes and
P2R1 and P2R2 for the two new nodes. The Current Cluster Configuration
contains one partition made up of a single Interval covering
the whole keyspace, while the Next Cluster Configuration contains two partitions:
P1 is made up of an Interval of the top half of the keyspace, and P2 is the
Interval of the bottom half of the keyspace.
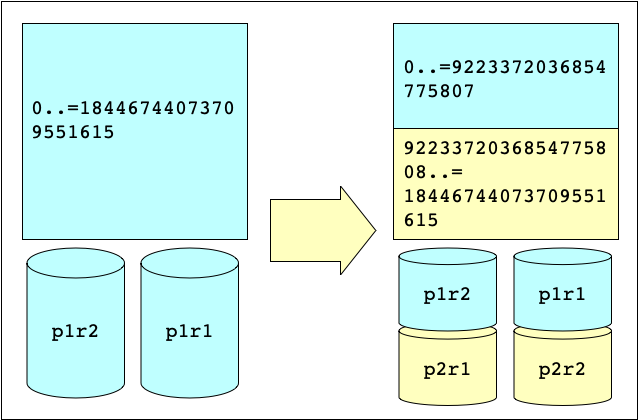
Backfill
The first stage of a Transition is Backfill. In our example we can
start P2R1 and P2R2 as new Big Peer Store Nodes, providing them
with the Current Cluster Configuration and the Next Cluster
Configuration. We also let P1R1 and P1R2 know about the Next Cluster Configuration,
so that they too know about the Transition.
As soon as P2R1 and P2R2 are brought online, they will start consuming from
the end of the transaction log. Using the Current Cluster Configuration, they can
send a Backfill Query to the current owners of any data they will own in the Next Cluster
Configuration. In this example, P2R1 and P2R2 send backfill queries to P1R1 and P1R2,
asking for the data from the bottom half of the keyspace.
Ownership and Gossip
During the Transition, Store Nodes gossip their view of the cluster to the union of all Store Nodes from both Cluster Configurations. Store Nodes also consume and store Transaction data that they might own in either the Current or Next Cluster Configurations.
In this example P1R1 and P1R2 continue to store transactions for
the whole keyspace during the transition.
New UST and Routing Configuration
The UST is calculated within the scope of a Cluster Configuration. The UST for the Next Cluster Configuration cannot be calculated until all Store Nodes in that Configuration are backfilled. Once Backfill is complete, the Store Nodes compare the UST in the Next Cluster Configuration with the UST in the Current Cluster Configuration. When the Next Cluster Configuration UST is equal or greater to the Current Cluster Configuration UST, it means that the Store Nodes in the Next Cluster Configuration have all the data they need, and can serve queries. A Store Node in the Current Cluster Configuration can now route queries to the Store Nodes in the Next Cluster Configuration. Each Store Node makes these calculations independently, based on received gossip messages.
In order to ensure that a Transition eventually completes, the UST in the Current Configuration stops rising once all Store Nodes in the Next Cluster Configuration have Backfilled. Since the new Store Nodes begin consuming from the Transaction Log before they begin to backfill, the UST in the Next Cluster Configuration should immediately match that of the Current Cluster Configuration. However, this might not be the case when we scale the Big Peer to a much larger number of nodes, given that the gossip time can slow the perceived rate of UST rise.
Installing new Cluster Configurations
As described above, read transactions occur at a given Read Timestamp, which is a pair of scalars, made up of the Cluster Configuration Epoch and the UST. The GC Timestamp is the locally calculated minimum of all Read Timestamps received by gossip. This means that each Store Node can independently calculate when all Store Nodes in the Current Cluster Configuration are routing queries in the Next Cluster Configuration, because all Read Timestamps are in the Next Cluster Configuration Epoch.
At this point, any of the Current Configuration Store Nodes can declare that the Transition is complete, and that the Next Cluster Configuration is installable as the Current Cluster Configuration.
When scaling down, nodes that are no longer in the Current Cluster Configuration can be shut down.
Garbage Collection
Garbage Collection also checks for ownership. Any data not owned by
the Store Node will be deleted. In the example above that means P1R1
and P1R2 can delete all the data from the bottom half of the
keyspace that is now owned, and safely stored, by P2R1 and P2R2.
Summary
This post described the process for transitioning a Big Peer Store cluster for scale up purposes. It describes the process in terms of two primitives: Transaction Timestamps and Cluster Configuration Epochs. This pair of scalars are composed to make the UST, Read Timestamps, and the GC Timestamp. Store Nodes gossip to each other about their Read Transactions and their latest consumed transaction, which allows each Store Node to independently calculate the progress of a Transition.
This post skips many implementation details of the engineering to ensure monotonicity, fault tolerance, and liveness of this process, for the sake of brevity.
Acknowledgements
With thanks to my colleague, Borja de Régil, for his review, edits and suggestions.